
BREACH : An oracle to steal your data
Introduction
CVE-2013-3587 aka BREACH is a security vulnerability against HTTP compression discovered in 2012 announced in 2013 at the Black Hat conference. It allows an attacker to steal secrets from encrypted HTTPS response under some specific conditions.
Although this vulnerability is difficult to exploit due to its many requirements, it is still exploitable on most recent https servers such as Nginx or Apache. Through this blog post, we will first dig into the mechanism behind the attack, then we’ll see how to build an exploit for the vulnerability. Finally, we’ll talk about ways to prevent such attacks.
Overview
The attack allows an attacker sniffing network traffic to guess secrets contained in an HTTP response body encrypted in a TLS session. To do so, the attacker must trick its victim into sending (a lot of) requests to a vulnerable web page reflecting some injectable user input, while sniffing the network to measure response packet length for each request.
Because of HTTP compression, the injected reflected data will be “compressed” with any identical string contained in response, resulting in a smaller TCP packet’s length. This principle can be used to build a discriminating oracle while brute forcing the injectable input, to predict whether an injected string is present or not in the response.
For this attack to succeed, the following conditions must be met:
- Web server using gzip compression for HTTP
- Attacker sniffing victim’s packets length (passive, or with MITM)
- A page reflecting a user input in the response body
- The same page containing a secret to steal in response body
- Victim opening a malicious link and keeping the tab opened long enough
Example
To understand better how such an attack could be performed in real life, let's take an example:
Alice is logged-in on her favorite web mail, in a modern web browser. Let's assume we are (as the attacker) sniffing the network. We send a malicious link to Alice pointing to a page displaying a loading screen, or any content that would convince Alice to keep the tab open as long as possible. Let's assume that Alice opens that link in her browser and keeps the tab open. In the background, the HTML page at that link is running a JS script, flooding her web mail client of requests on a specific page: /index?info=. Let’s assume these requests are provided with Alice’s cookies by the browser, so they are authenticated requests.
Of course, it is assumed that the Access-Control-Allow-Origin header is properly set (or unset) on the web mail server, so the sent requests cannot obtain their responses, otherwise this whole attack would be useless. However, if responses are not accessible to the malicious script, they still do flow over the network and their lengths are measurable thanks to network sniffing.
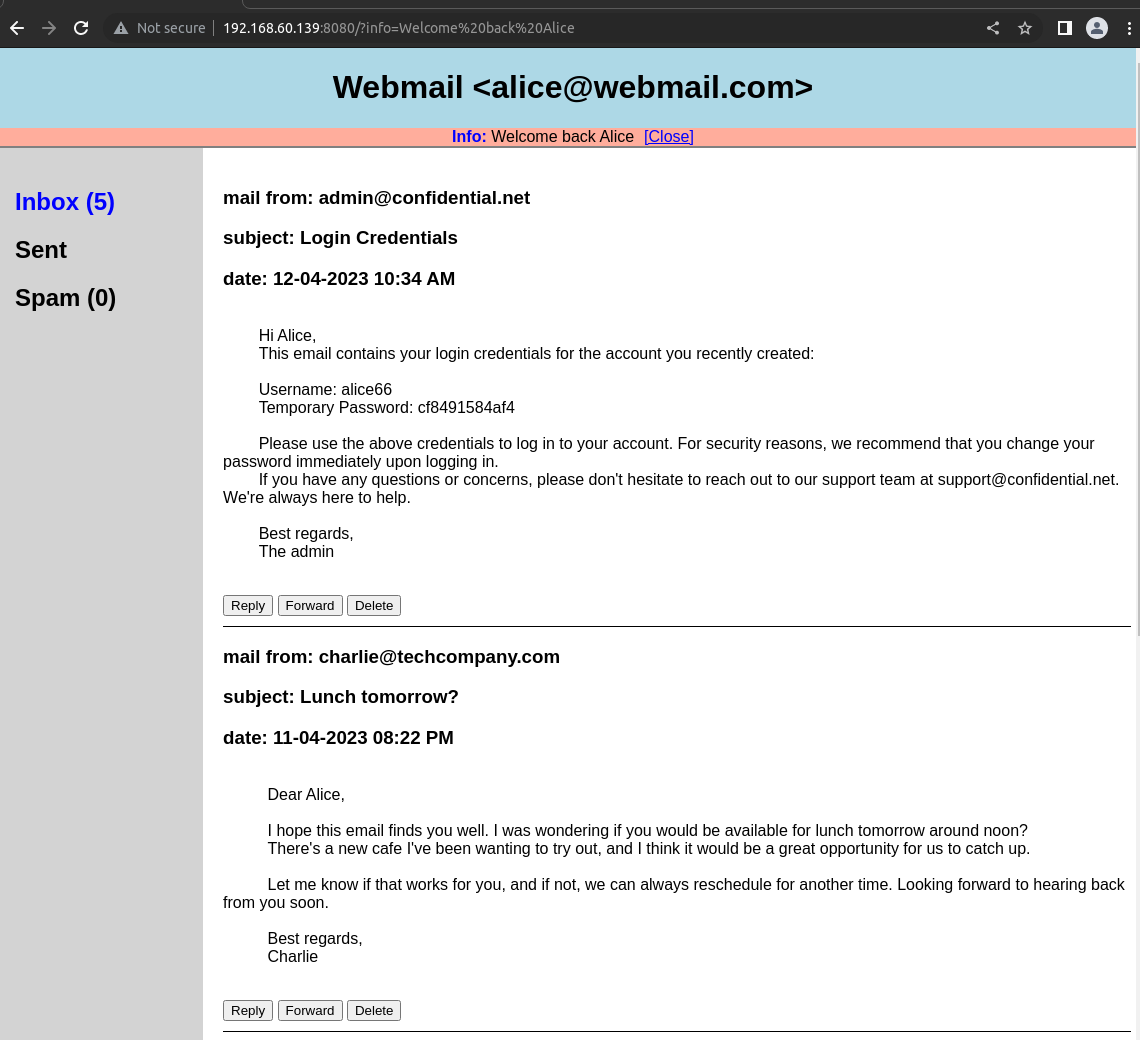
The targeted page /index is the homepage of Alice’s webmail, it shows a list of recent received mails, but it also admits a GET parameter info, displaying an informative banner at the top of the page with the parameter value reflected as text. Even if this parameter is properly sanitized and does not allow for any code injection, it still reflects user input, which makes the whole page vulnerable to our attack.
By requesting /index?info=[guess], and by prefixing [guess] with a known substring found in the page, we can brute force and guess the data present in the page right after the specified prefix, by trying to minimize the response length. We simply use the response length to discriminate good guesses from bad ones.
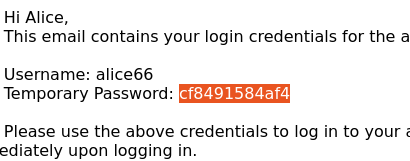
Let’s assume Alice’s last received mail contains a secret Temporary Password: cf8491584af4. By requesting /index?info=Temporary%20Password:%20[guess] and by brute forcing [guess] with the right charset, it is likely that the response (page’s body) length will be minimal for [guess] = "c" rather than for any other character. Once c is guessed, we can repeat the brute force process to guess cf then cf8 then cf84 until we finally guess the whole Temporary%20Password:%20cf8491584af4 string. Although there are some techniques to know when the secret is finished, the best way is to know the total secret length before starting the attack. Most of time, that length is easily predictable. Through this process, we can guess mostly any data in the page, as long as we are able to prefix/suffix/contextualize it enough to “start” the attack.
This is the main principle of the attack and if you were looking for a global understanding of the attack, you can stop there.
However, in practice, it is a bit more complicated as the gzip compression algorithm does not simply compress identical substrings together. Therefore, the lowest response length is too often found for a wrong guess/false positive to let us perform an efficient attack.
To understand how to build an efficient and real life working exploit, let's have a deeper look into the HTTP compression algorithm.
DEFLATE, the gzip algorithm
DEFLATE, the algorithm responsible for compression behind gzip, used in HTTP, is using a combination of LZ77 and Huffman coding. LZ77 is a kind of dictionary coder, meaning it looks for repeated occurrence of data, to replace next occurrences with a reference to the first occurrence. It simply codes a tuple <distance, length> for each new occurrence of a repeated token, specifying the relative distance to the last identical token, and its length. This part of the deflate algorithm is “friendly for the attacker” as it reduces the compressed length of data containing identical patterns. It means it reduces the response length when our guess is similar to the secret we're brute forcing.
The Huffman coding is the second part of the DEFLATE algorithm. It allows to encode each symbol of a given alphabet, with a variable number of bits, in such a way that most frequent symbols are coded on fewer bits than the rarest ones. It is proven to be optimal, meaning it provides the optimal encoding for each symbol to maximize the mean entropy per symbol and minimize data’s length (considering the given alphabet is a linear independent set). This algorithm, as elegant as it may be, becomes our biggest enemy here. If a guess contains frequent symbols (so with little coding length), even if completely different from the secret, it may result in a lower response length than with a correct guess. And as we have no idea of the charset distribution of the page’s body, we cannot counter that bias easily.
Note: In some situations, we can have a fairly accurate idea of the charset distribution. When the page contains little of user data and the structure of the page is known, or when the language of user data on that page is known (as the distribution can often be approximated using its language average distribution). It is probably feasible, and it may improve the accuracy of the attack, but it complexifies it too. It was not tested for this post.
Finally, because of the Huffman coding, the DEFLATE algorithm result in a compressed data made of bits, not bytes. Some padding is added if necessary to round the compressed data bits count to an integer number of bytes. Therefore, two requests can result in the same length as measured on the network while resulting is different bits length with DEFLATE, if that difference is lower than 8 bits. Let’s call that phenomenon the “DEFLATE byte-rounding”.
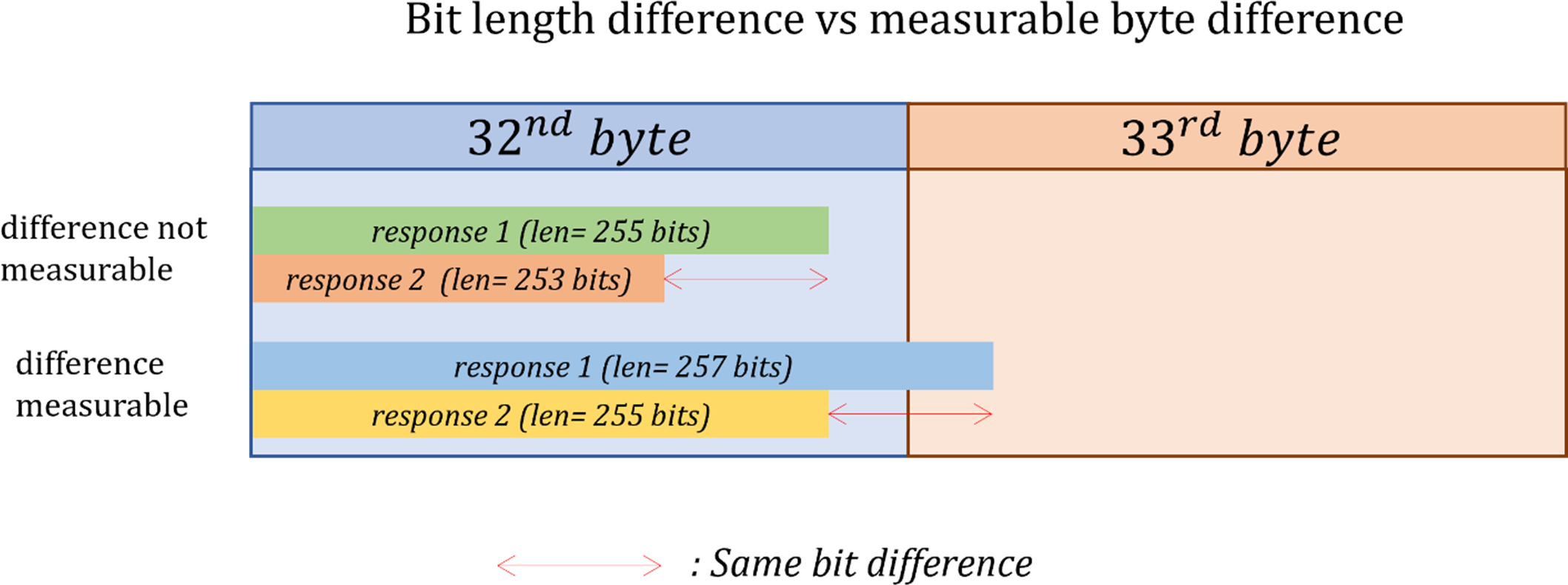
Guesses discrimination techniques
To build an exploit for this vulnerability, we “just” need to build a strong guess-discriminating algorithm. We can model our problem as a blackbox function taking a guess as an input and returning a number (the response length) as an output. Let's call that function CRL([string]) for Compressed Response Length.
To counter the Huffman coding, a first approach consists of comparing a guess with a variant of itself, instead of comparing it with other guesses, so that the charset distribution remains unchanged. For example, if
CRL([prefix] + "..." + [guess]) > CRL([prefix] + [guess] + "...")
it would mean “breaking” the string [prefix]+[guess] in two parts makes it heavier to store (more bits required), which suggests [prefix] + [guess] is likely to exist as a whole substring in the original response body.
It is still not 100% accurate as [prefix] + [guess] + "..." could just compress better than [prefix] + "..." + [guess] only because of its content, for example blabla... would compress better than blab...la. But this behavior can be mitigated by the exploit as the compressed length of the injected string itself is known (lz77 being deterministic).
The string "..." used there is the separator. It must be a word very unlikely to be found in page, and whose substrings are very unlikely to appear too. For the explanation, "…" was chosen but in our exploit, we better use something more sophisticated, with rare characters.
Also, some subsets of [prefix] + [guess] are also likely to be found on the page, especially subsets made of few characters. To avoid taking those cases as false positive while brute forcing, we can move the separator within the few last characters of the prefix itself such as [prefix_part1] + "..." + [prefix_part2] + [guess] then measure the length for various positions of the separator. If the length varies a lot depending on that position, it may imply that the tested string is a false positive.
Finally, to mitigate the DEFLATE byte-rounding, several different separators can be used to increase the measure precision (by averaging different measures).
Doing all those kinds of checks gives an idea of which guess looks plausible and which does not. But it does not provide a way of classifying guesses against each other.
Score ranking & tree exploration algorithm
To do so, we need to build a “score” for each guess, based on those techniques. The idea for the algorithm is to give each guess a score, then to select the best ones (guesses with the lowest score, with some tolerance or not). These guesses then become the new prefixes, and the algorithm brute forces these prefixes again. It works like a tree, exploring and deepening its branches by selecting the best ones at each level, to avoid exponential growth of guesses to try. This will be the main brute force algorithm behind our exploit.
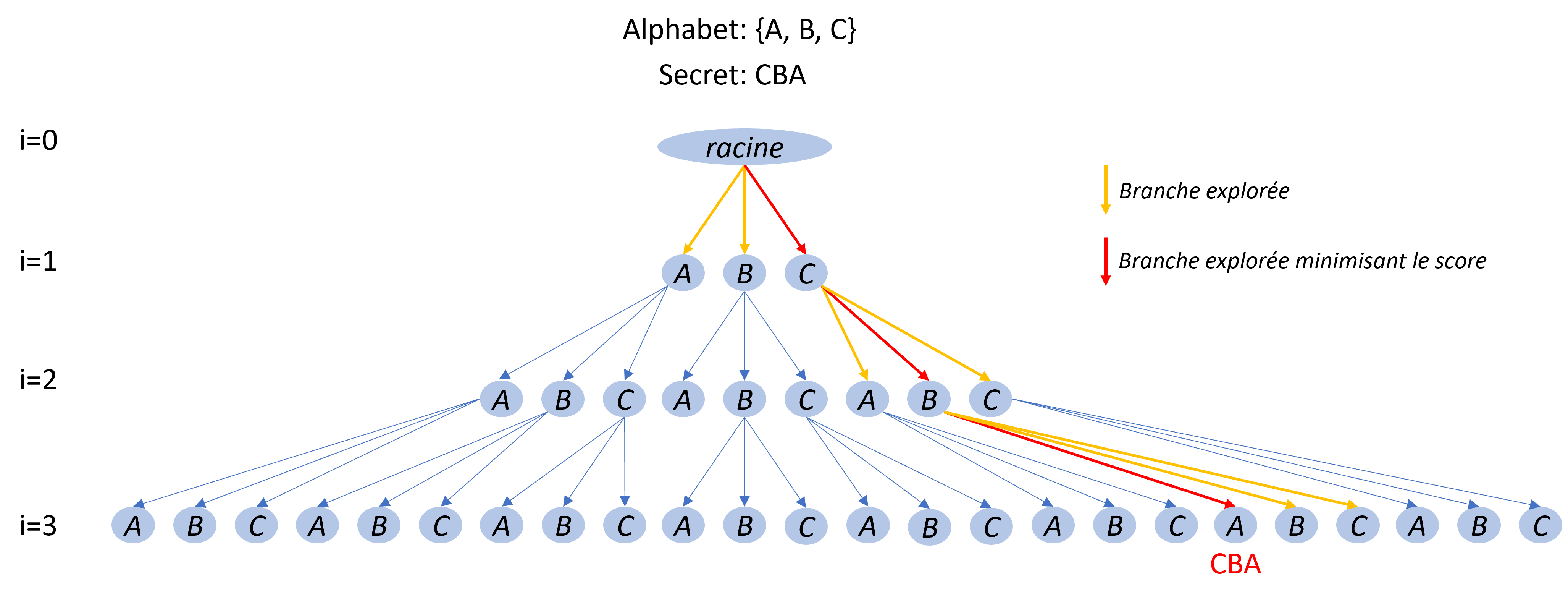
To build a score for every guess, we can add or subtract the responses lengths of requests described in all previously described techniques, keeping in mind the goal is to provide a lower score for more plausible guesses.
A pretty accurate score can be given (formula comes from previous explained techniques):
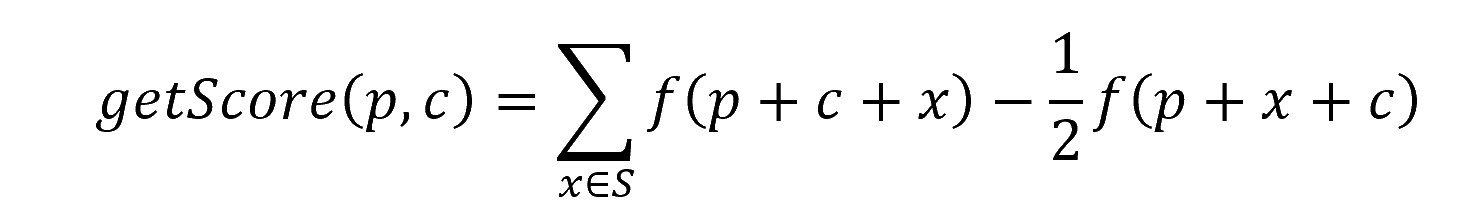
With
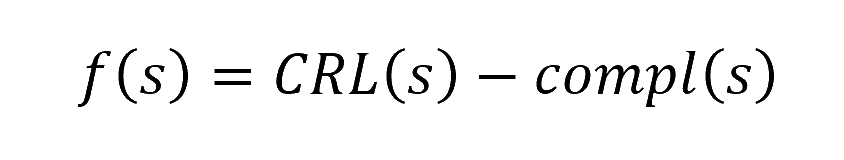
And
- p the prefix
- c the tested caracter
- S the separator set (contains different separator with different lengths)
- CRL(s) the CRL black box function for the given string s, in byte
- compl(s) the length (in byte) of the compressed given string s using the DEFLATE algorithm
In practice, it requires about 6 requests per guess to compute the score, which gives quite good efficiency. The ½ factor is arbitrary but it was working good.
Implementation
This section will detail critical points of the actual exploit implementation that require further explanation.
The attack requires the victim to keep a tab open on their computer, on an attacker-controled website. This website must make request toward a vulnerable page on which the victim is authenticated on. Unfortunately for the attacker, cookies and especially authentication ones do not always get provisioned on cross-site request. This depends on the “same-site” cookie attribute, and on the browser used. Using the website SameSite Cookies Tester (samesitetest.com), the following matrix can be obtained:

The YES and NO answer the question “is the cookie with the following attributes provided on requests of that kind ?”. To give an example, XHR GET requests do get provided with cookies on Firefox, except for the ones with the “same-site=strict” attribute.
If the authentication cookie is strict, then the attack will always fail for those browsers. And an XHR doing a GET requests maximize attacker chances to succeed its attack.
Here’s an example with a “Samesite: None” cookie on 127.0.0.1:8080 :
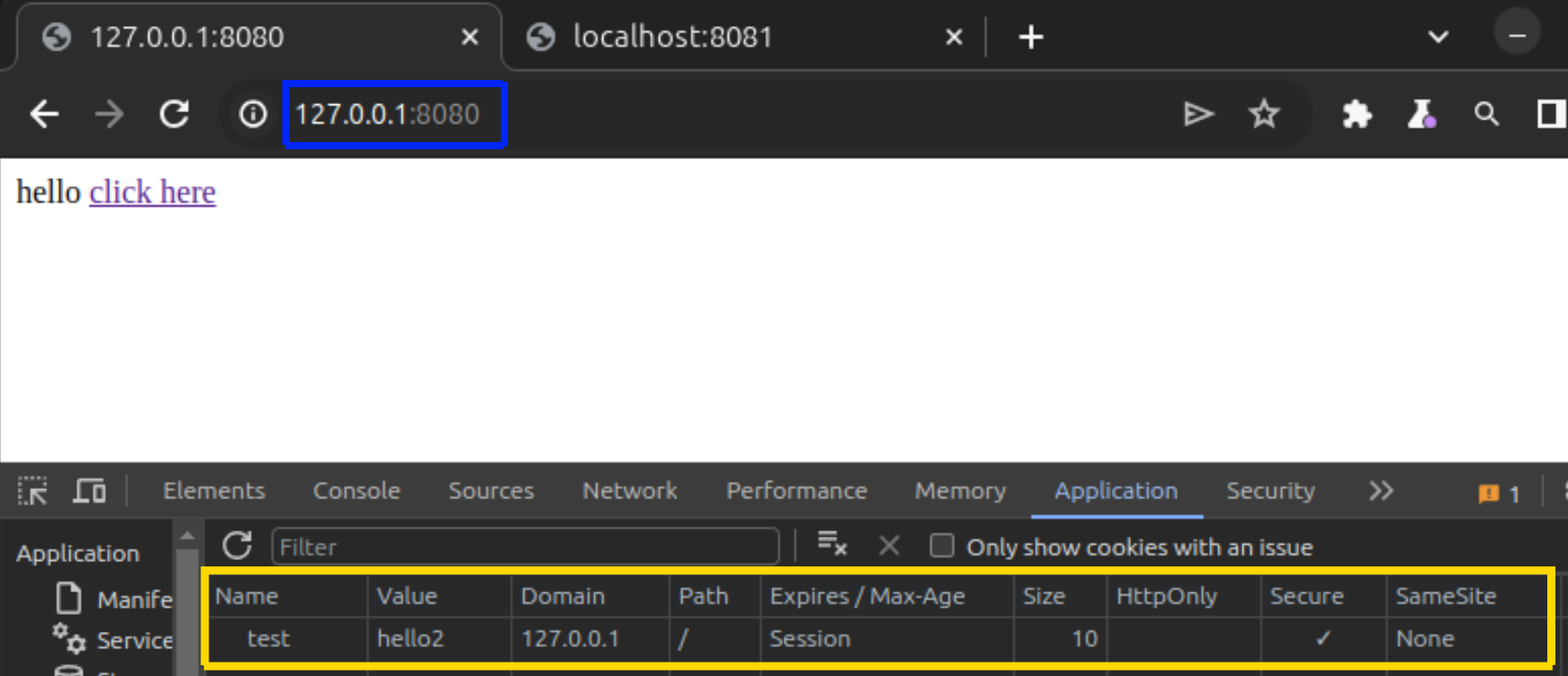
From another tab of the browser on a different origin (localhost:8081), a request is made to the first origin:
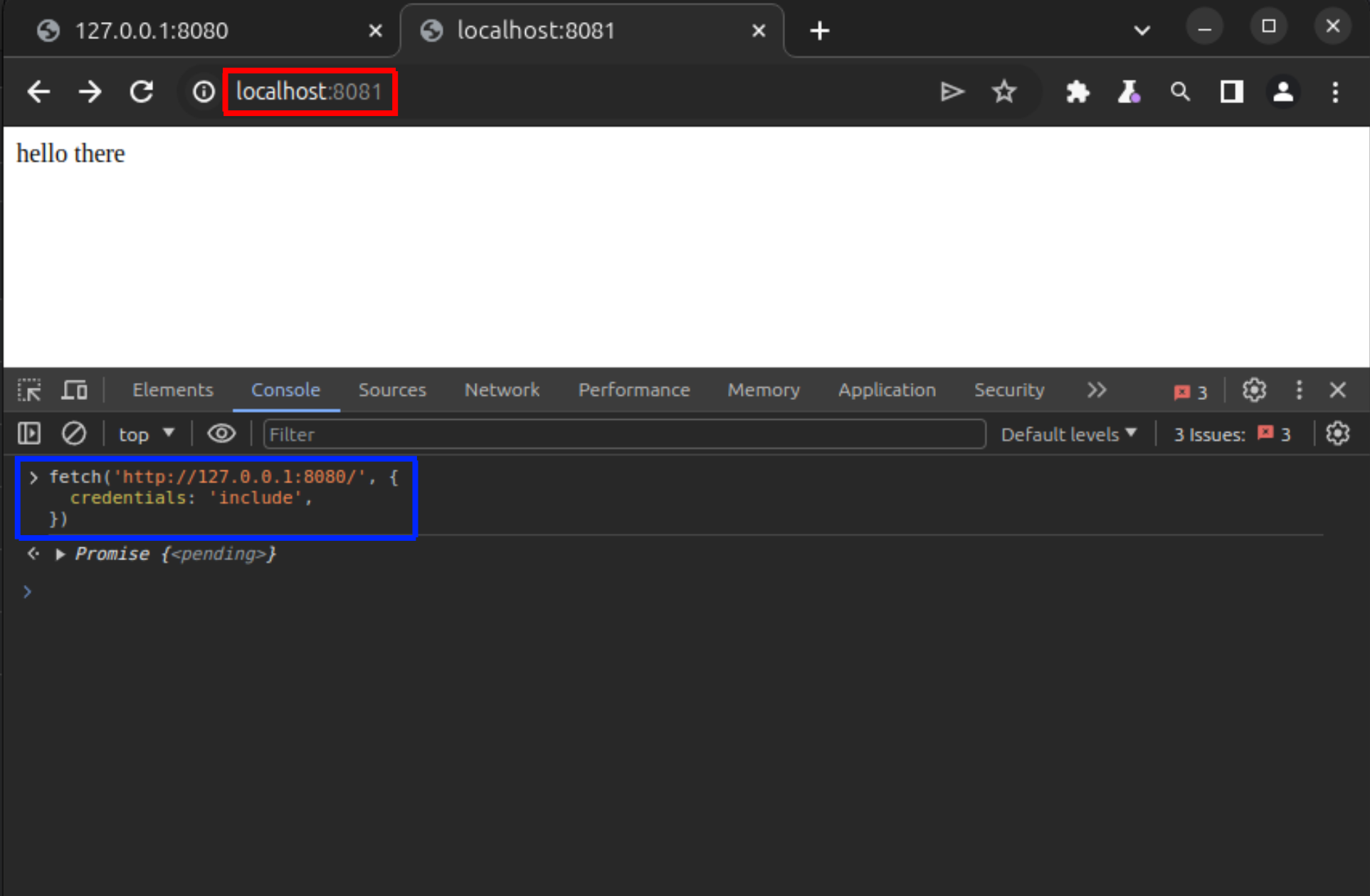
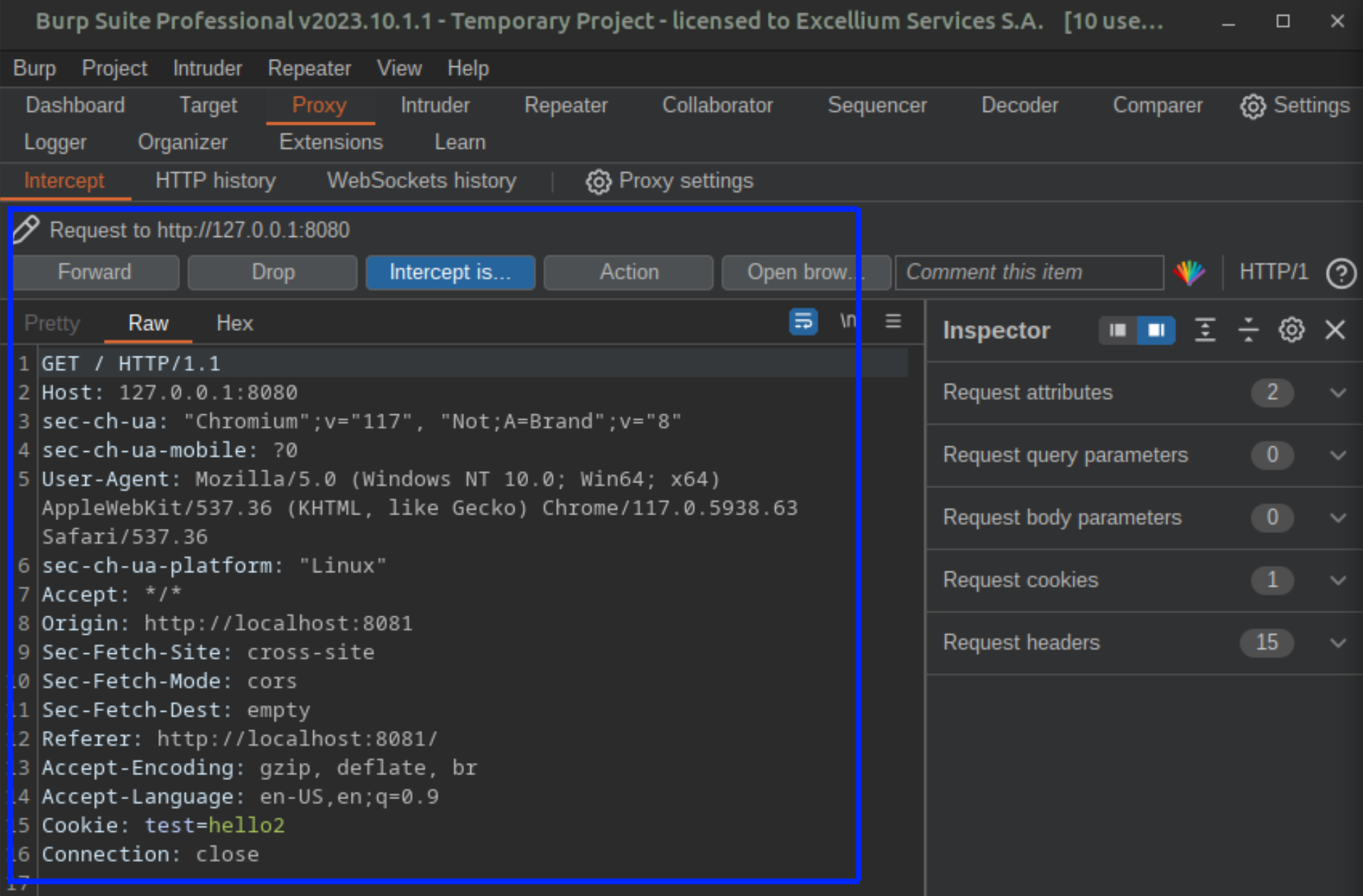
When intercepted using Burp proxy, this request from localhost:8081 to 127.0.0.1:8080 is actually provided with the 127.0.0.1:8080 cookie.
The second point which needs to be highlighted is about eavesdropping, and more exactly about the traffic correlation. The goal for the attacker is to send requests from the victim’s browser, then to capture the corresponding TLS packet flowing on the network to measure its payload’s length. This is quite obvious if the attacker-controlled website tab is the only process doing request to the vulnerable domain, as network traffic can be filtered on source and destination IPs, however if the victim is not exactly on the same local network as the attacker (as behind a router, with other users producing traffic on the targeted domain) or if the victim/its computer is producing traffic on the targeted domain, both traffics can become difficult to distinguish.
Those two technical “real-life” points add even more condition on the attack to succeed.
Results
The exploit was made in Python using Scapy for the network sniffing. Here's how it looks like on Alice vulnerable webmail, while trying to steal the following credentials:
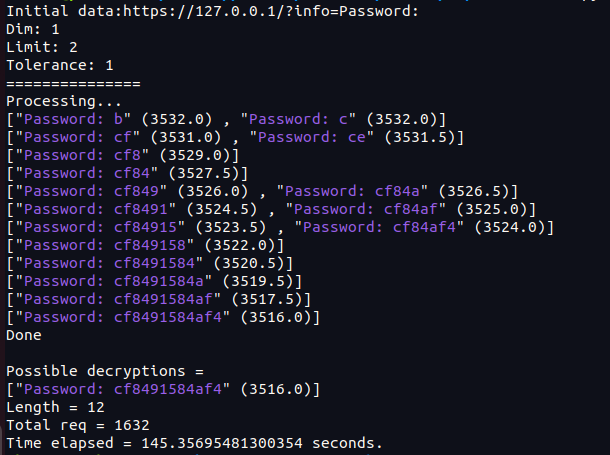
We can see every selected branch in the processing phase, associated with its score.
In less than 3 minutes, the secret was stolen.
To measure the performance of the exploit, experimental tests are run on Alice’s webmail demo website, using randomly generated hexadecimal secrets (a small charset makes it fast to run).
We will compare two models:
- The naive model, simply using CRL([prefix]+[guess]) as the score
- The new model, using the score formula described earlier
Each configuration is tested 1000 times. Every time, the algorithm returns the 5 most plausible secrets it found, with the score associated to each potential secret.
The success rate for a model is measured as the percentage of time the real secret is found within the 5 most plausible guesses returned by the exploit. This indicator will be called top5.
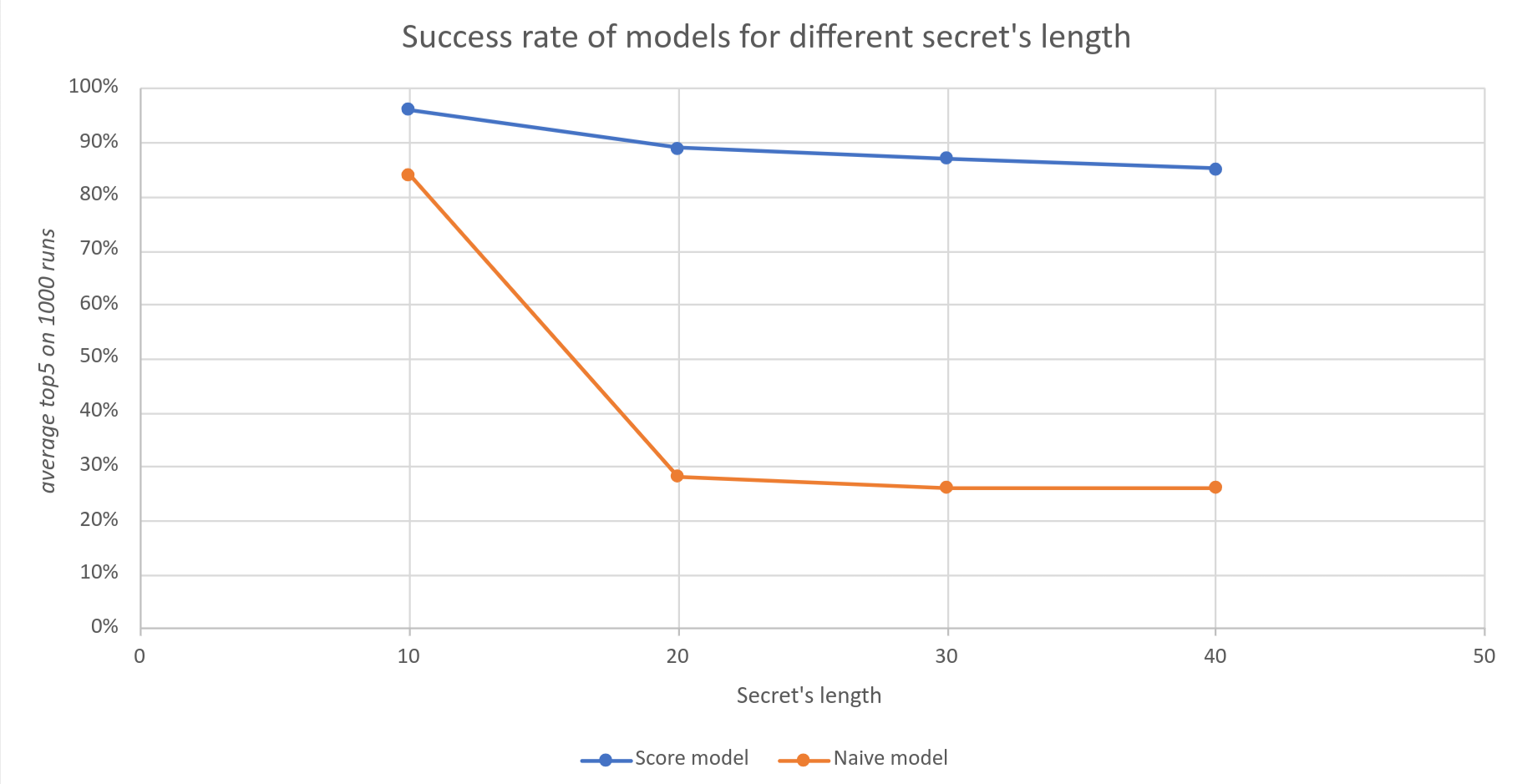
The new model clearly outperforms naïve model performances. The success rate seems to decrease slowly when the secret’s length increases, which shows the model resilience.
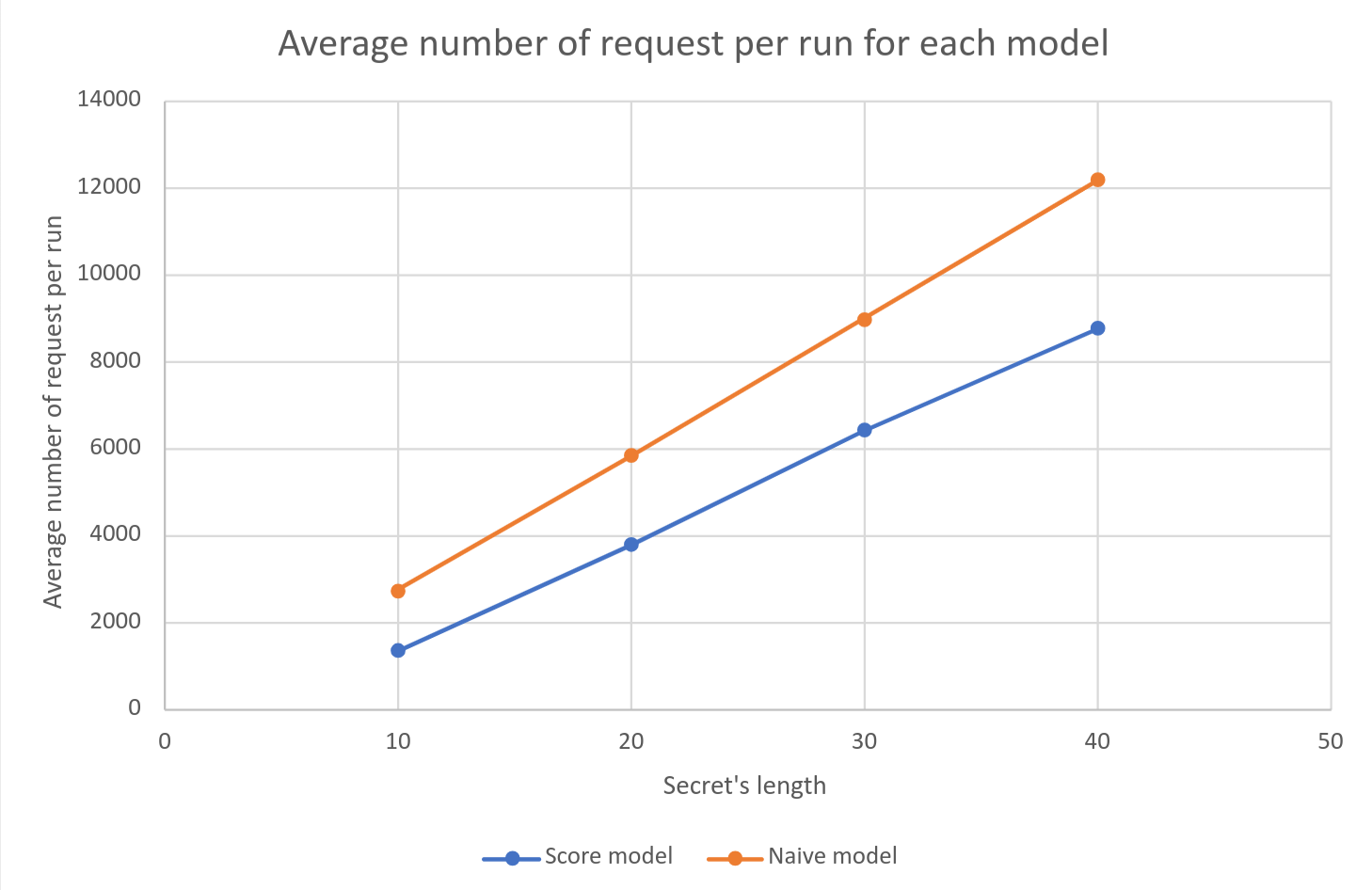
Pretty logically, the new model is stealthier than the naive one, doing way less requests as it is more efficient. It is important to note that while the new model does 6 requests per “branch explored” in its tree exploration algorithm, the naïve model only does 1 request. Which means the naïve model not only produces more requests but it explores over 6 times more branches for worst results.
Finally, considering a ping of a few milliseconds, under good conditions, the BREACH attack could be performed using this exploit, on 40 bytes long secret, within two minutes.
The current exploit’s bottleneck is the traffic correlation as it induces more delays in the length measurement process than the requests round trip.
Prevention
How can we prevent such an attack? First, let’s keep in mind BREACH requires many conditions to be met on the same page, which is unlikely. Back in 2013, when this vulnerability was released, a lot of fixes were proposed, such as SafeDeflate, deBreach or HealTheBreach. The two first ones are variants of the DEFLATE algorithm, preventing LZ77 to compress data using a specified alphabet, or tagging the secret to avoid it being compressed at all. HealTheBreach tries to add deterministic randomness to the response length in order to make it harder to guess anything. Even if it definitely complexifies the attack, randomness can always be defeated by averaging a lot of samples together.
To avoid such an attack, the rule is simple: Do not compress data containing both sensitive information and user inputs. At least not when the compressed size can be measured on the network.
Conclusion
In summary, the BREACH vulnerability is still a thing nowadays even if it requires many conditions. To prevent it, disable HTTP compression on your server for dynamic resources. To exploit it, build the oracle and a branch exploration algorithm as described in this blog post.
Authors
References
- Gluck, Harris and Prado (2013). “BREACH: SSL gone in 20 seconds”.
- Feldspar (1997). An Explanation of the Deflate Algorithm.
- Rees-Carter’s SameSite Cookies Tester


